
せっかくScraping(スクレイピング)しようとしたのに、開始早々にブロックされてしまって出鼻を挫かれてしまったというような経験をされたことがある方も少なくないのではないでしょうか。
そのような方はbright dataという有料プロキシサービスを活用することをおすすめします。bright data(ブライトデータ)を活用すると、ブロックを防止しながら迅速かつ容易にScraping(スクレイピング)が実行できるためです。
そこでこの記事では、Scraping(スクレイピング)でブロックされてしまった時の試すべき方法をはじめ、そもそもブロックを予防するための方法や、bright data(ブライトデータ)を活用する意義などについて、解説していきます。
目次
そもそもスクレイピングとは
まずはじめにScraping(スクレイピング)について、概要を抑えておきましょう。
Scraping(スクレイピング)とは、特定のデータを収集した上で、利用しやすいように任意の形式に加工することを言います。
具体的には、最初の段階でどのような情報が欲しいのかを定義した上で、その情報がWebサイト及びデータベースのどの部分に記載されているのかを探り、可能性のあるページなどを自動的に周って情報を抽出及び加工することになります。
ときには、人工知能(AI)の機械学習のためのデータ識別を人間の目で行う必要がある場合などでは、一部は手作業でScraping(スクレイピング)を実行する場合もあります。
Scraping(スクレイピング)技術があれば、とても便利にデータ抽出及び加工ができますが、悪意がなくても、場合によっては法律違反となったり、トラブルに発展したりしてしまう場合があるので注意が必要です。
- 取得したデータをデーか解析以外に利用する
- データ取得先のWebサイトに負荷を与える
- Webサイト自体がScraping(スクレイピング)を禁止しているにもかかわらず実行する
特に上記のようなことにならないよう、注意しましょう。
もちろん取得したデータを許可なく公開及び販売したり、コピーして配布したりなどは、著作権法によって禁止されています。さらに、取得先のWebサイトに負荷を与えるということは偽計業務妨害罪に当たると判断されてしまうこともあり、実際に2010年には、岡崎市立中央図書館の蔵書システムにアクセスし、図書情報をScraping(スクレイピング)していたとして、逮捕された実例もあります。逮捕された人物は悪意はなかったことから、私たちも悪意がなくScraping(スクレイピング)を行っていたとしても、場合によっては逮捕されてしまうなんてことも起こりうるのです。
また、法律違反までいかなくてもWebサイトの利用規約でScraping(スクレイピング)を禁じている旨が明記されているのにも関わらず実行すると、Webサイト運営者より民事訴訟を起こされる可能性もあるため、きちんと利用規約を確認することが大切です。
スクレイピングをブロックするサイト運営者側の考え
Scraping(スクレイピング)の取得先のWebサイト運営者がScraping(スクレイピング)をブロックする理由を知っておくと、なぜブロックされたのか、逆にどうすればブロックされないのかが見えてきます。
Webサイト運営者がブロックする理由としては、主に次の3つが考えられるでしょう。
- 一般ユーザーによるアクセスでないのならそもそもシャットアウトしたい
- Webサイト訪問者数の増加によるサーバーの負荷をなるべく軽減したい
- そもそもScraping(スクレイピング)自体を行われたくない
上記のように、Scraping(スクレイピング)に限らず、不正アクセスやサーバー負荷の面から、Scraping(スクレイピング)自体もブロックする仕組みを構築していることもしばしばあるのです。
スクレイピングがらWebサイトを守るためのブロック方法
Webサイト運営者は、Scraping(スクレイピング)から自分のWebサイトを守りたいと思った時、主に次の2点の方法でブロックすることが多いです。
- CAPTCHA
- IPアドレスブロック
CAPTCHA
CAPTCHAとは、正式名称で「Completely Automated Public Turing test to tell Computers and Humans Apart」と表記され、オンラインユーザーがbotではなく、本物の人間であるかどうかを判断するために設計された、完全に自動化された公開チューリングテストのことです。
インターネットを使用していると、アカウント作成時をはじめ、ログイン時やオンライン投票、ときには電子商取引チェックアウトページなどで、時折歪曲された文字が表示され、その文字を指定のフォームに入力するよう求められたり、画像の中から特定の物をクリックするように求められたりすることがありますが、この仕組みがまさにCAPTCHAによる、人間かbotかを判断するものとなります。
中でも最も有名なCAPTCHAのサービスは、Google社が提供しているreCAPTCHAであり、一般的なCAPTCHAよりも高度とされています。
IPアドレスブロック
IPアドレスブロックとは、同一のIPアドレスから通常とは異なる多数のリクエストが検知されたりするときにそのIPアドレスをブロックすることです。
cookieなどは偽造できることで有名ですが、IPアドレスは偽造することができないため、1つのIPアドレスで特定のWebサイトに不自然な膨大なリクエストを送信してしまうと、人間ではなくbotであると認識されてしまい、IPアドレス自体がブロックされることになります。
スクレイピングがブロックされてしまった時
Scraping(スクレイピング)をせっかく開始したのに、ブロックされてしまった時、試すべき3つの方法についてご紹介していきます。
- リクエストの頻度及び速度を遅くしてみる
- デバイス及びルーターを再起動してみる
- IPアドレスをローテーションしてみる
リクエストの頻度及び速度を遅くしてみる
1つのWebサイトに対して、あまりにも高頻度で膨大なリクエストを行ってしまうと、そのWebサイトのサーバーの負荷が増大してしまいます。さらに高頻度かつ膨大なリクエストというだけで、人間ではなくbotによるアクセスであるのではないかと運営者に疑われ、サーバー負荷を軽減させる目的と合わせてIPアドレス自体をブロックされてしまうのです。
そこで、Scraping(スクレイピング)したい取得先のWebサイトのサーバーに負荷をかけることがないように、リクエスト自体の頻度を減らしてみたり、Scraping(スクレイピング)の速度を遅くしてみたりしてみることをおすすめします。そうすることで、botと認識されず、ブロックを防ぐことができるかもしれません。
ただし、この場合には、データ抽出自体の効率が著しく下がってしまうということを覚悟しなければなりませんので注意してください。
デバイス及びルーターを再起動してみる
ときにはデバイスやルーターなどのトラブルによって、Googleのメッセージ「通常と異なるトラフィック」が表示される時がありますので、その場合には1度デバイス及びルーターを再起動してみると、Scraping(スクレイピング)をブロックされてしまっている問題が解決することもあるので試してみてください。
IPアドレスをローテーションしてみる
Scraping(スクレイピング)が実施できないという時の最も想定できる要因は、IPアドレス自体がブロックされてしまうということです。
この場合には、IPアドレス自体を違うものに変えたり、ローテーションして使用するとWebサイト側では多くの人間のユーザーがリクエストをしてきているように見えるので、複数のIPアドレスを用意することが最も簡単な対応策であるといえます。
スクレイピングのブロックを避けるためには?
これまでなぜScraping(スクレイピング)がブロックされてしまうのかをはじめ、ブロックされたしまったときに試してみると良い方法などを解説してきましたが、そもそもScraping(スクレイピング)のブロックを予防する方法がいくつかありますので、この項目では次の2つをご紹介します。
- プロキシを活用してみる
- 有料プロキシbright data(ブライトデータ)が最もおすすめ
プロキシを活用してみる
プロキシとは、ユーザーがサーバーへアクセスする際にユーザーの代理を担うシステムのことであり、世の中には様々なプロキシサービスが存在しています。
プロキシサービスを活用すると、主に次のような恩恵を受けることができます。
複数のプロキシサーバーを利用した場合
複数のプロキシサーバーを利用すると、ブロック回避と効率的なデータ収集が容易に実現できます。
複数のIPアドレスを利用した場合
複数のIPアドレスを利用すると、1つのWebサイトに対して、同時に別のIPから自然に複数のリクエストを送信することができます。そのためbotと認識されずに容易にデータ収集可能です。
住宅用プロキシを利用した場合
住宅用プロキシを利用すると、地域データであっても容易にアクセスすることができます。
有料プロキシbright data(ブライトデータ)が最もおすすめ
プロキシサービスには、無料のものも有料のものもあり、どのサービスを選んで良いか悩まれるかもしれませんが、最もおすすめのサービスはbright data(ブライトデータ)といえます。
bright data(ブライトデータ)は、世界で最も使用されている有料プロキシサービスであり、データ収集インフラをはじめ、既成のデータセットに至るまで、欲しいと思う公開Webデータを他のプロキシサービスより遥かにスムーズに取得することができます。
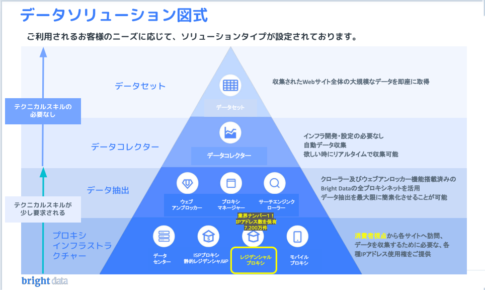
bright data(ブライトデータ)のサービスの概要
bright data(ブライトデータ)には、次のような様々な種類のサービスがあります。
- Data Collector(データコレクター)
- Search Engine Crawler(サーチエンジンクローラー)
- Web Unlocker(ウェブアンロッカー)
- Proxy Network(プロキシネットワーク)
Data Collector(データコレクター)
Data Collector(データコレクター)とは、世の中に公開されているあらゆるWebデータを大規模で収集するためのbright data(ブライトデータ)の一元管理プラットフォームのことであり、コードを使用せずにScraping(スクレイピング)を行うことができるものです。
サービスにはセルフサービスとフルサービスの2種類が存在しており、取得先のWebサイトからデータを収集するためにカスタムコレクターを作成するか否かで選択できます。
Search Engine Crawler(サーチエンジンクローラー)
Search Engine Crawler(サーチエンジンクローラー)とは、ユーザーのデバイス上で、自ら作成したデータセットをもとに、簡易操作でジオターゲティングを実行しながら、Googleなどをはじめとする主要検索エンジンから正確なSERPデータ(サーチエンジン検索結果画面データ)を収集できるものです。
このデータ収集の際には、それぞれのリクエストは異なるIPアドレス(全世界でおよそ7,200万以上)から送信されることになるため、ブロックされることはありません。
Web Unlocker(ウェブアンロッカー)
Web Unlocker(ウェブアンロッカー)とは、様々なWebサイトでのブロックを克服しており、Scraping(スクレイピング)を行うことができるものです。
従来あらゆるWebサイトにおいて、自動的にIPアドレスをブロックするための新しい方法が日々開発されているなか、Web Unlocker(ウェブアンロッカー)は、リアルタイムで調整し、botとして検出されないよう、データーセンターあるいは固有IPアドレスを使用します。
もちろん1つのIPアドレスからbotと疑われるようなリクエストを要求することなく、取得先のWebサイトにおいて、まるで人間が操作しているかのようなマウス捜査を行いつつ、リクエストの間隔を一定ではなくランダムに自然に設定することで、Scraping(スクレイピング)をスムーズに実施できます。
Proxy Network(プロキシネットワーク)
Proxy Network(プロキシネットワーク)では、業界最大と言っても過言ではない世界の各地域を網羅しており、さらに4つのサービスに分類されます。
- Datacenter Proxies(データセンタープロキシ)
- Residential Proxies(レジデンシャルプロキシ)
- ISP Proxies(ISPプロキシ)
- Mobile Proxies(モバイルプロキシ)
Datacenter Proxies(データセンタープロキシ)
Datacenter Proxies(データセンタープロキシ)とは、世界中の公開Webデータを匿名で99.99%の確率で収集することができ、実に150,000以上もの企業で採用されているプロキシサービスとなっています。
もし初めて利用する場合でも、簡単なドキュメンテーションが用意されていることから、安心して利用できるだけでなく、プロキシの管理はbright data(ブライトデータ) Proxy Managerによって行われます。
Residential Proxies(レジデンシャルプロキシ)
Residential Proxies(レジデンシャルプロキシ)とは、世界中の国及び都市に存在する7,200万以上を誇る実在の家庭用IPアドレスで構成されており、botとは気づかれることなく自然にScraping(スクレイピング)を実施することができます。
ISP Proxies(ISPプロキシ)
ISP Proxies(ISPプロキシ)とは、世界の150,000以上もの企業に採用されており、600,000以上の完全準拠の静的住宅用プロキシを誇るものです。業界最速と言われる応答時間でユーザーはストレスなく利用することができ、精度の高い情報収集を行うことができます。
Mobile Proxies(モバイルプロキシ)
Mobile Proxies(モバイルプロキシ)とは、実に何百もの携帯電話の3G及び4GのIPアドレスを活用することにより、ブロックを削除するだけでなく、自動モバイルIPs回転とCAPTCHAを回避することができるものです。
bright data(ブライトデータ)の料金体系
bright data(ブライトデータ)の料金体系は、前述したサービスの種類によって細かく設定されていますが、従量課金制、月額プラン、年間プランがあるので、使用頻度などによって最も適したものを選択することができるのも嬉しいポイントの1つと言えるでしょう。
また、下記4つのサービスに限り、法人アカウントであれば7日間だけ無料トライアルも利用できるので是非試してみるのも良いでしょう。
- Data Collector(データコレクター)
- Web Unlocker(ウェブ アンロッカー)
- Residential proxies(レジデンシャルプロキシ)
- Mobile proxies(モバイルプロキシ)
まとめ
Scraping(スクレイピング)でブロックされてしまった?bright dataなら安心?ブロックを予防する方法について、この記事では、Scraping(スクレイピング)でブロックされてしまった時の試すべき方法や、bright data(ブライトデータ)を活用する意義などについて、解説してきました。
Scraping(スクレイピング)を効率的かつストレスフリーで行うためには、有料プロキシサービスであるbright data(ブライトデータ)がとても有効であることがご理解いただけたのではないでしょうか。
Scraping(スクレイピング)の度にブロックされて疲弊していた方は、今すぐbright data(ブライトデータ)を利用してみてください。
Bright Dataは、ユーザーに役立つツールと情報を開発・提供しています。インターネット上の情報をビジネスに活用したい人は、是非ともBright Dataと契約してください。
<参考資料>
https://saas-navi.com/proxy/web-scraping-block/
https://data.wingarc.com/scraping-27053
https://www.sbbit.jp/article/cont1/71102
https://www.cloudflare.com/ja-jp/learning/bots/how-captchas-work/
https://jp.scrapestorm.com/tutorial/inteoduce-some-scraping-prevention-and-countermeasures/
https://www.ctcsp.co.jp/itspice/entry/093.html










コメントを残す